A Quick Primer on KL Divergence
This is the first post in my series: From KL Divergence to Variational Autoencoder in PyTorch. The next post in the series is Latent Variable Models, Expectation Maximization, and Variational Inference.
The Kullback-Leibler divergence, better known as KL divergence, is a way to measure the “distance” between two probability distributions over the same variable. In this post we will consider distributions and over the random variable .
It’s beneficial to be able to recognize the different forms of the KL divergence equation when studying derivations or writing your own equations.
For discrete random variables it takes the forms:
For continuous random variables it takes the forms:
And in general it can be written as an expected value:
To build some intuition, let’s focus on the following form:
Notice that the term is the difference between two log probabilities: . So, the intuition stems from the fact that KL divergence is the expected difference in log probabilities over . Although not entirely technically correct, imagine the following to help build an intuition: consider two, perhaps similar, univariate probability density functions and and imagine sliding across the domain of and observing the difference at every point. This is kind of how KL divergence quantifies the “distance” between two distributions.
Now, a couple of important properties that I won’t prove:
The asymmetric property begs the question: should I use or ? This leads to the subject of forward versus reverse KL divergence.
Forward vs. Reverse KL Divergence
In practice, KL divergence is typically used to learn an approximate probability distribution to estimate a theoretic but intractable distribution . Typically will be of simpler form than , since ‘s complexity is what drives us to approximate it in the first place. As a simple example, could be a bimodal distribution and a unimodal one. When thinking about forward versus backward KL, think of as fixed and as something fluid that we are free to mold to .
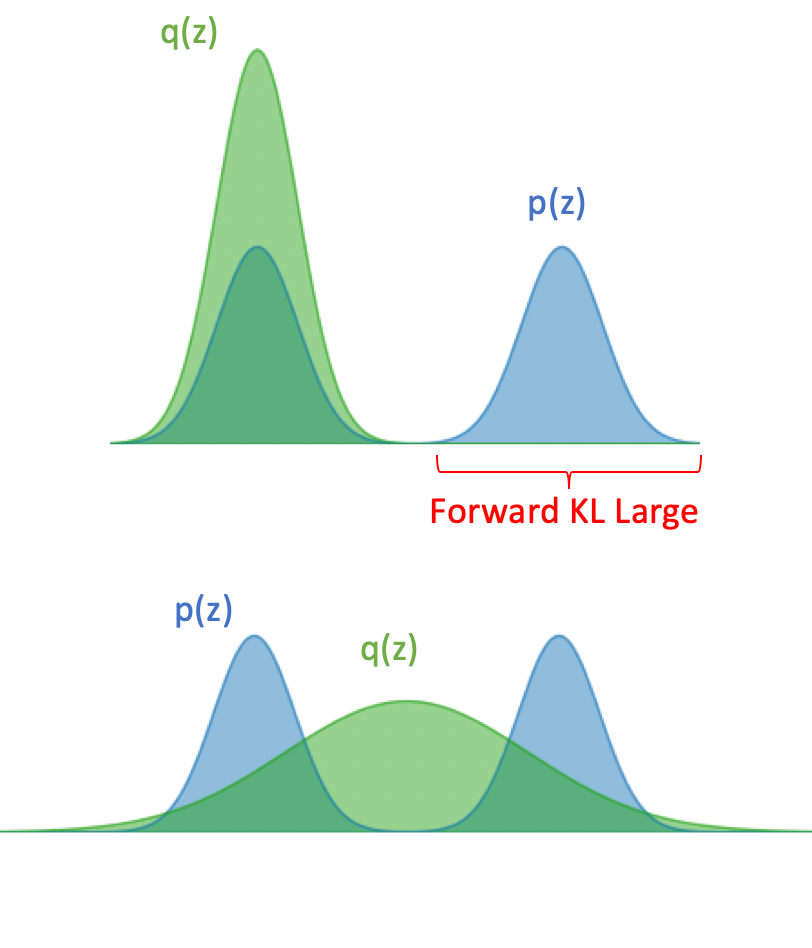
Forward KL takes the form
As you can see from this equation and the figure below, there is a penalty anywhere that is not covering. In fact, if in a region where , the KL divergence blows up because . This results in learning a that spreads out to cover all regions where has any density. This is known as “zero avoiding”.
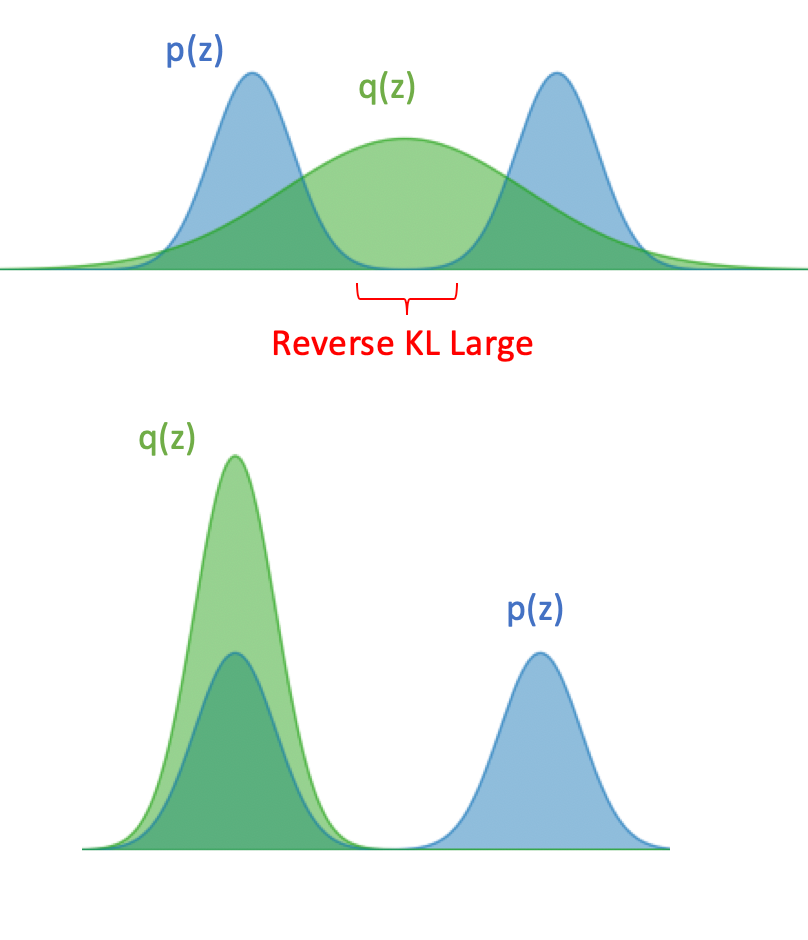
Reverse KL takes the form
As seen from the equation and the figure below, reverse KL has a much different behavior. Now, the KL divergence will blow up anywhere unless the weighting term . In other words, is encouraged to be zero everywhere that is zero. This is called “zero-forcing” behavior.
For example, if has probability density in two disjoint regions in space, a with limited complexity may not be able to span the zero-probability space between these regions. In this case, the learned would only have density in one of the two dense regions of .
Conclusion
KL divergence is roughly a measure of distance between two probability distributions. There are different forms of the KL divergence equation. You can bring a negative out front by flipping the fraction inside the logarithm. You can also write it as an expectation.
Numerous machine learning models and algorithms use KL divergence as part of their loss function. By exploiting the structure of the specific model at hand, the KL divergence equation can often be simplified and optimized via gradient descent.
KL divergence is asymmetric and it’s important to understand the differences between forward and reverse KL.
My next post builds on KL divergence to explore latent variable models, expectation maximization, variational inference, and the ELBO.
Resources
[1] Eric Jang, A Beginner’s Guide to Variational Methods: Mean-Field Approximation